🧐SEEAvatar: Photorealistic Text-to-3D Avatar Generation with Constrained Geometry and Appearance
Yuanyou Xu1, Zongxin Yang1, Yi Yang1
1 ReLER, CCAI, Zhejiang University
Photorealistic avatars represented in meshes and textures generated from text prompt by our method, exported to Blender for offline rendering, with additional 3D assets for building scenes.
Photorealistic avatars represented in meshes and textures generated from text prompt by our method, exported to Unreal Engine for real-time rendering, with additional 3D assets for building scenes.
Abstract
- Powered by large-scale text-to-image generation models, text-to-3D avatar generation has made promising progress. However, most methods fail to produce photorealistic results, limited by imprecise geometry and low-quality appearance. Towards more practical avatar generation, we present SEEAvatar, a method for generating photorealistic 3D avatars from text with SElf-Evolving constraints for decoupled geometry and appearance.
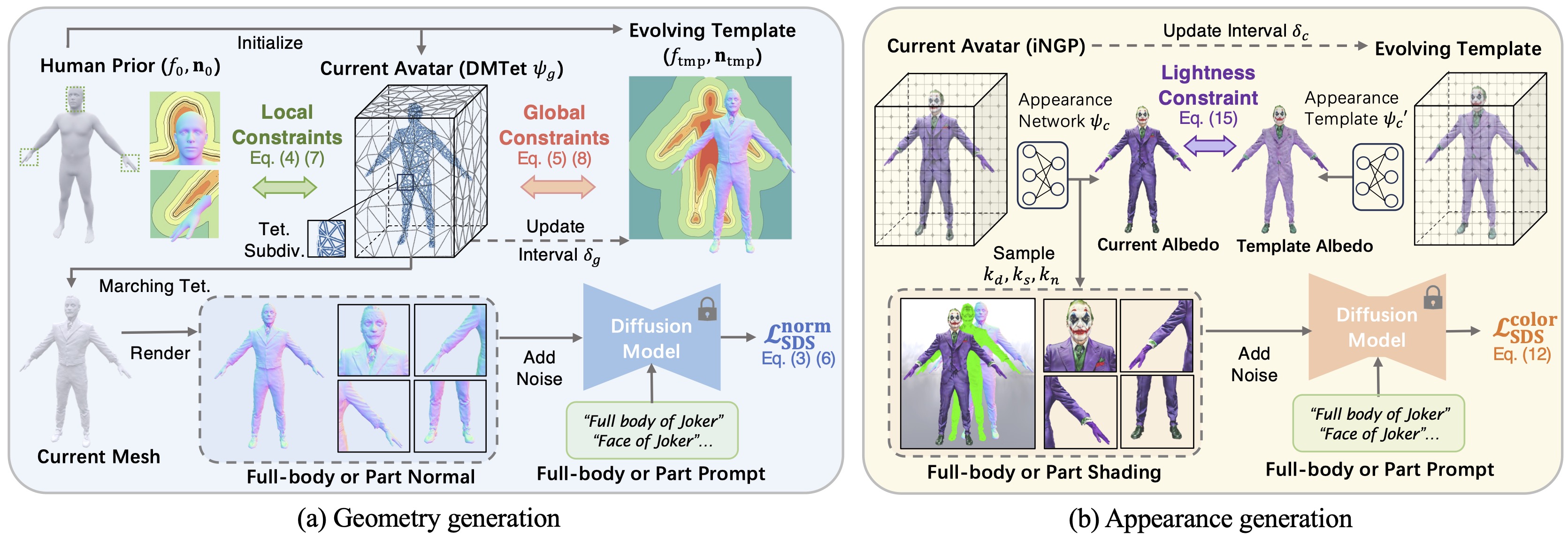
- For geometry, we propose to constrain the optimized avatar in a decent global shape with a template avatar. The template avatar is initialized with human prior and can be updated by the optimized avatar periodically as an evolving template, which enables more flexible shape generation. Besides, the geometry is also constrained by the static human prior in local parts like face and hands to maintain the delicate structures.
- For appearance generation, we use diffusion model enhanced by prompt engineering to guide a physically based rendering pipeline to generate realistic textures. The lightness constraint is applied on the albedo texture to suppress incorrect lighting effect.
- Experiments show that our method outperforms previous methods on both global and local geometry and appearance quality by a large margin. Since our method can produce high-quality meshes and textures, such assets can be directly applied in classic graphics pipeline for realistic rendering under any lighting condition.
Results
All avatars are generated and rendered in full-body manner. Heads are rendered in a larger size for better view.
Batman
Joker
Spiderman
Abraham Lincoln
Barack Obama
Hillary Clinton
Ludwig van Beethoven
Wolfgang Amadeus Mozart
Vincent van Gogh
Captain Jack Sparrow
Doctor Strange
Elsa in Frozen
Comparison
Comparison with text-to-avatar methods, NeRF-based DreamWaltz and mesh-based TADA.
Animation
Generated avatars are animated by retargeting motion sequences from Mixamo.
Joker turning around
Spiderman swinging
Bruce Lee kicking
Relighting
Generated avatars are lighted by multiple lights with different colors from different angles.
Joker lighted
Spiderman lighted
Bruce Lee lighted
Citation
@article{xu2023seeavatar,
title={SEEAvatar: Photorealistic Text-to-3D Avatar Generation with Constrained Geometry and Appearance},
author={Xu, Yuanyou and Yang, Zongxin and Yang, Yi},
journal={arXiv preprint arXiv:2312.08889},
year={2023}
}
Abstract
- Powered by large-scale text-to-image generation models, text-to-3D avatar generation has made promising progress. However, most methods fail to produce photorealistic results, limited by imprecise geometry and low-quality appearance. Towards more practical avatar generation, we present SEEAvatar, a method for generating photorealistic 3D avatars from text with SElf-Evolving constraints for decoupled geometry and appearance.
- For geometry, we propose to constrain the optimized avatar in a decent global shape with a template avatar. The template avatar is initialized with human prior and can be updated by the optimized avatar periodically as an evolving template, which enables more flexible shape generation. Besides, the geometry is also constrained by the static human prior in local parts like face and hands to maintain the delicate structures.
- For appearance generation, we use diffusion model enhanced by prompt engineering to guide a physically based rendering pipeline to generate realistic textures. The lightness constraint is applied on the albedo texture to suppress incorrect lighting effect.
- Experiments show that our method outperforms previous methods on both global and local geometry and appearance quality by a large margin. Since our method can produce high-quality meshes and textures, such assets can be directly applied in classic graphics pipeline for realistic rendering under any lighting condition.
Results
All avatars are generated and rendered in full-body manner. Heads are rendered in a larger size for better view.
| Batman | Joker | Spiderman |
|---|
| Abraham Lincoln | Barack Obama | Hillary Clinton |
|---|
| Ludwig van Beethoven | Wolfgang Amadeus Mozart | Vincent van Gogh |
|---|
| Captain Jack Sparrow | Doctor Strange | Elsa in Frozen |
|---|
Comparison
Comparison with text-to-avatar methods, NeRF-based DreamWaltz and mesh-based TADA.
Animation
Generated avatars are animated by retargeting motion sequences from Mixamo.
| Joker turning around | Spiderman swinging | Bruce Lee kicking |
|---|
Relighting
Generated avatars are lighted by multiple lights with different colors from different angles.
| Joker lighted | Spiderman lighted | Bruce Lee lighted |
|---|
Citation
@article{xu2023seeavatar,
title={SEEAvatar: Photorealistic Text-to-3D Avatar Generation with Constrained Geometry and Appearance},
author={Xu, Yuanyou and Yang, Zongxin and Yang, Yi},
journal={arXiv preprint arXiv:2312.08889},
year={2023}
}